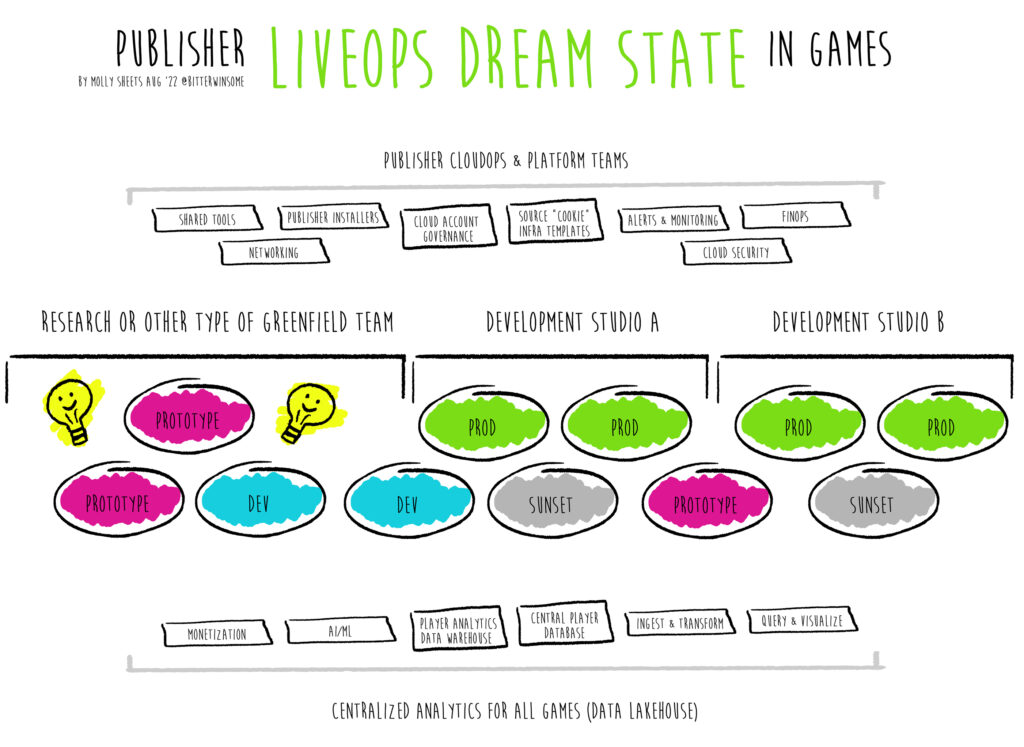
I’ve been experimenting with ChatGPT this weekend after seeing Simon Cornelius P. Umacob try it with cloud architectures in other fields. It’s awesome – and I am so glad to be living at this moment in my life. I played with it far more than I captured on video. I asked ChatGPT to walk me through, like any engineer or architect I would hire, the steps to build specific workloads – a Game API for purchasing, build farms, matchmaking algorithms. I greatly struggled to get it to say the word “Kubernetes” on its own. It definitely picked up some common patterns in microservices and serverless workflows using SQS, ECS, Lambda and provided context to those decisions. That’s impressive.
What’s fascinating to me is just how much ChatGPT was able to demonstrate that it knows. It feels like a true rubber-duck collaborator in that regard. But I know, just like many, that there is a delta between what it outputs and what is in my brain.
That delta will get smaller – ChatGPT will be an excellent partner to programmers, managers, and designers and is a new way to troubleshoot and search. Imagine Git repositories, Stack Overflow, and automated code generation tools like Amazon Code Whisperer all in the worlds greatest search and you have ChatGPT.
Will it replace engineers and architects? Absolutely not. It still gets a lot of things wrong — I know where we are today by living in the problem and thus I also recognize architectural patterns and choices that are dated. I believe that in many fields this will be the case, not just games, where experts or those who have lived will see wider deltas between what they have seen, the training, new knowledge and the parallelized speed with which we can feed information and it can output a hivemind that doesn’t keep us in…stasis. After all, how does ChatGPT handle injection of innovation if innovation in architecture starts off in a silo before it ever becomes a hive.
We have to remember that AI is always fed and trained. I saw it output historically old patterns. They aren’t that old is the thing, they just aren’t exactly what I’d use. They are vague and lack detail. ChatGPT can’t get into the nuances with high performant workloads – but it can close the gap in the discovery phase. I can imagine two cases where this is an accelerant in engineering (1) I’m building a workload in a space or field for which I’ve never seen and (2) I’m an engineer who just graduated.
To see my first experiments with ChatGPT designing games architecture, check out these videos:
Part 1: ChatGPT, Design a Game API for Purchases & Matchmaking
Part 2: ChatGPT, Design a Build Farm
Part 3: ChatGPT, Design a 65 player Matchmaking Algorithm
I’d like to put fuel on that fire – I’d like to install this tool on an internal server and feed it everything I can externally and internally and see what happens.
I know the problems with what it outputs which is why ChatGPT can be used to get people up to speed to where you are, but what it can’t do is replace those who have to look around corners. You’re not losing your job tomorrow. Not for this anyway.
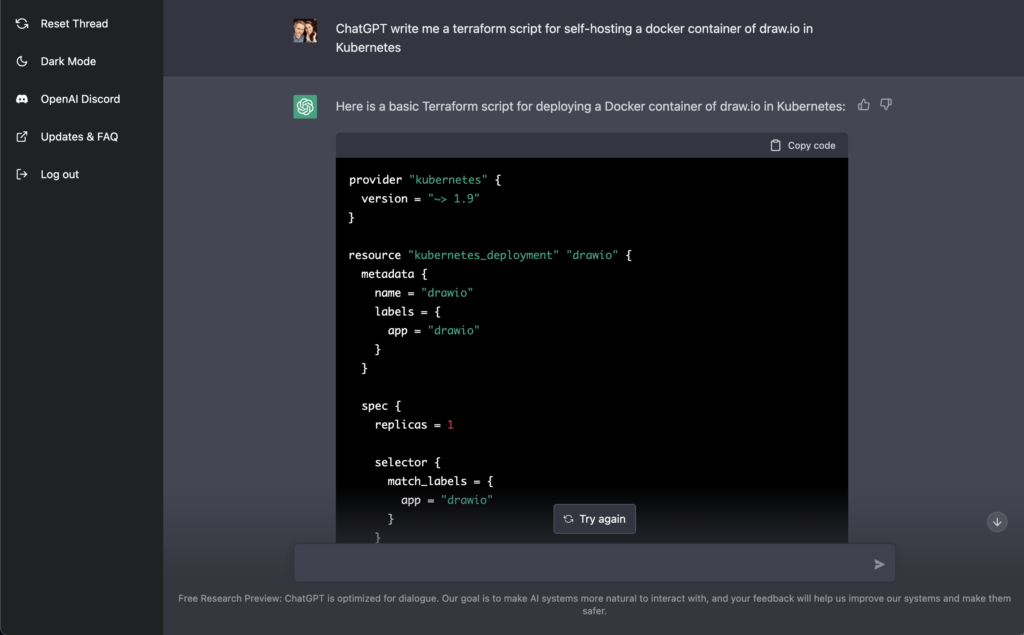
If I’m lucky enough to have you read anything I’ve ever written, you may have guessed I like to find the delta (you probably do too). In the delta, there is always opportunity, but you have to measure it. This is how I knew I wouldn’t lose my job: “ChatGPT write me a terraform script for self-hosting a docker container of draw.io in Kubernetes.” My new OpenAI Jr architect engineer wrote this.
provider "kubernetes" {
version = "~> 1.9"
}
resource "kubernetes_deployment" "drawio" {
metadata {
name = "drawio"
labels = {
app = "drawio"
}
}
spec {
replicas = 1
selector {
match_labels = {
app = "drawio"
}
}
template {
metadata {
labels = {
app = "drawio"
}
}
spec {
containers {
name = "drawio"
image = "jgraph/drawio:latest"
ports {
container_port = 8080
}
}
}
}
}
}
ChatGPT, like blogs released by actual people who do not want to get sued, added this comment “This script creates a Kubernetes deployment with a single replica of the jgraph/drawio:latest Docker image. The container will be listening on port 8080. Keep in mind that this is a very basic example and may not be suitable for production use. It is recommended to further customize the deployment based on your specific requirements.”
Therein likes the crux. This delta is massive. Living the exercise that is trying to deploy only this single template to production as one who knows nothing about Kubernetes or cloud requires humans to understand the context for what is missing in this script, for where it will sit, for who needs to monitor it, and all the people who will use it. Context remains one of the most difficult aspects to translate into AI. Which is why the future of AI — and those who will be empowered by it — are those who will find a way to balance both the strength of internal contexts with those of the outside world using self-hosted algorithms that are amplified by the combined expertise of both.
Perhaps if we feed ChatGPT screenshots of code it will learn the value of pull requests to guide CEOs based on the user logged into its account. Perhaps it will benefit from being fed comments from Git. Someday ChatGPT and others like it may close the delta between what one can use in production and what is only, a microcosm of complexity that lies in stacks enterprises manage today, adopt an extremist view of GitOps, write its own code, and self-deploy.
But probably not.