“Test Drive” by From “How to Train Your Dragon” by John Powell ???? Image Credit: Image of Polaris (“The North Star”) and the Integrated Flux Nebula taken by then 14-year-old Kush Chandaria astrophotographer in ’21 / Wikipedia (CC BY-SA 4.0).
On June 30th AWS released the CSI driver for Amazon FSx for OpenZFS for Kubernetes. If you are working on that – you’re awesome. After reading that Vela Games used OpenZFS to solve their build problems, I circled that blog to industry friends who knew me on a deep level – I have to know. I’ve seen mostly what doesn’t work….for now 3 years. I’ve talked about the problem for a long time. To get to the best solutions, you have to really, really, really understand the problem.
Fresh reminder: This is how hard it is to make a game today

(Click the image to enlarge)
Maybe this isn’t the storage solution for version control, builds, and auxiliary workloads to builds. Maybe we’re stuck with EBS as half of what we want. Maybe I’m still wrong. Storage for builds? It’s that hard of a problem.
In the blog Amazon states, “Vela stores artifacts in FSx for OpenZFS. The CI pipelines can access these artifacts to run multiple jobs in parallel, such as fast intermediate file sharing and running the Derived Data Cache from Unreal Engine…When compiling code or cooking assets are complete, BuildGraph copies the resulting artifacts from that job to FSx for OpenZFS. Vela uses the long-lived shared storage to retain intermediate results across sequential jobs that would otherwise be deleted after the job is complete. Subsequent jobs can use these results to skip a lengthy initialization process and run much faster.’”
I read it. Then I read it again.
I spent 2 years looking at storage problems around games repositories and builds and end user streaming delivery of clients. If I had to summarize 2020-2022 and how I even came to Kubernetes – I never felt like I was close enough to the problem.
Talk About The Problem
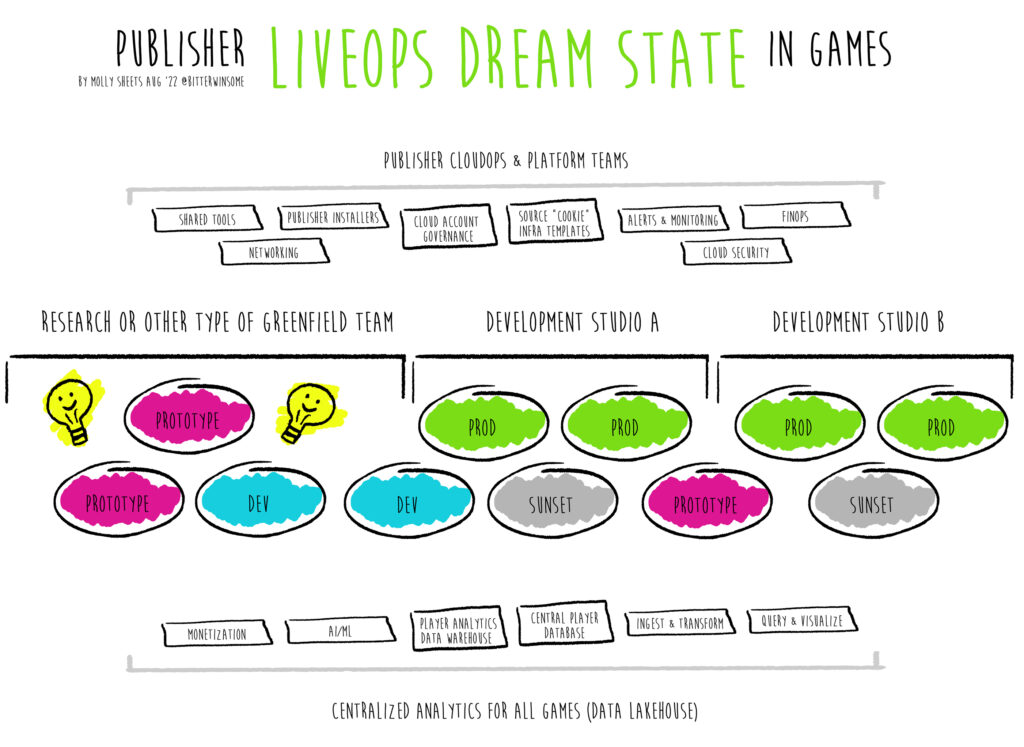
Speaking historically, educationally, about public things that have already happened, and not on behalf of Zynga – Game teams wanted to use Kubernetes because they could run a mini cloud where they can isolate workloads but still have 1 control plane. They still had to solve the storage challenges tied to specific use cases for those workloads that need dedicated storage – the data, objects, and files needed to provide the services running in clusters. For version control, build, and testing use cases, the industry thought we wanted file storage over block storage for game repositories that are used in architecture patterns but needed the speed of block storage (which is how Perforce Helix core often lands at this design). Teams also use Git LFS in Github Enterprise, JFrog Artifactory, and a bunch of other tools. The industry was paralyzed (instead of parallelized) by the lack of variety connecting Kubernetes to fast storage options when it came to ReallyBigGames™ to the point of being locked into hybrid workloads, unable to migrate from on-prem fully, or forced into EBS-based storage and designing architectures that are fundamentally handcuffed by speed and networking. If you want to feel that pain point, design literally any functional workload (builds, scans, testing) that involves a shared massive game repository of assets and client-side code as its source (not server-side) and aim for “real time” results.
Do it. I’ll wait. Literally.
This isn’t to say that teams didn’t migrate or move in the last 5 years to the cloud in an effort to make shorter builds and more feature rich pipelines – they absolutely did. And complicated build farms have existed for years. However lack of variety for high throughput and high IOPs in the cloud meant developers struggled to clone fast enough, the biggest games were “datacenter locked’ if you will to be ready to access repos against the changes to that data, constantly resizing volumes, and scarce solutions that support team-shared version control all while really, deep down, wanting file storage. Forget even trying to tie that to kubernetes and microservices in a way that was not horrifically complicated. That was all happening at the same time. As I said, I am speaking historically. I lived through that – starting before I joined Amazon praying that Unity Cloud Build would make this use case less terrible desiring for it to solve all my problems as a managed solution. Which it did not (but was very promising!!!). Then I saw how tough this all was deeply and tried to fix it, and then it just kept getting weirder and more fun. So here we are today: Back at OpenZFS…opensource implementation of ZFS file system and volume manager created by Sun Microsystems… (Hi…Chris)
From the documentation about Amazon FSX for OpenZFS: “FSx for OpenZFS file systems can serve network I/O about three times faster than disk I/O, which means that clients can drive greater throughput and IOPS with lower latencies for frequently accessed data in cache.“
To really understand how I would get to “Oh god – I think this CSI Driver for OpenZFS is worth trying and I’m wondering what works and what breaks” you need to read the technical comparison.
Part 1: The Technical Part
Let’s talk about block storage because it’s fast. Please take a look at this IOPs chart for EBS pulled from the EBS documentation – if you want to know what to benchmark against for a use case involving games repos and storage, you have to look at IOPs and also Amazon EBS Multi-attach. I picked SSD because I want to compare EBS gp3 but also EBS io2 volumes against file storage with OpenZFS. I care a lot about “Max IOPS per volume,” “Max throughput per volume,” and Amazon EBS multi-attach – and whether it’s supported with the tools people use with Kubernetes (it’s not) or if it will require writing a driver (yuck). So the good news is, you can use EBS with Kubernetes today with the official Amazon EBS CSI Driver. But not with multi-attach.

But, as I said before, deep down – many devs really wanted, this whole time, a file store and landed at “whatever worked” even if it was horrifically slow. Even I did when I worked on this to use FSx as a file store to load repositories for streaming workstations if you didn’t want to use Perforce Helix Core with EBS and really wanted a file store. “It works” but, I’m here to tell you, that was PART ONE and both solutions had challenges. Upon reflection – I know we can do better.
Let’s talk about EFS and why it doesn’t work well with big repositories and version control. The below graph is taken from the EFS documentation on performance. Please note this is where it is today. I include it in order to compare to the above more easily. Max IOPs and throughput becomes a problem if you’re constantly syncing a bunch of small tiny files.

Now let’s look at OpenZFS performance. According to the OpenZFS documentation – “If you select Automatic provisioned SSD IOPS, Amazon FSx will provision 3 IOPS per GB of storage capacity up to the maximum of 160,000 for Single-AZ 1 and 350,000 for Single-AZ 2, which is the highest IOPS level supported by the disk I/O connection… If you select User-provisioned, you can configure any level of SSD IOPS from the minimum of 3 IOPS per GB of storage, up to the maximum 160,000 IOPS for Single-AZ 1 and 350,000 IOPS for Single-AZ 2, as long as you don’t exceed 1000 IOPS per GB.”
It’s very hard to compare these services because they look at this data with slightly different glasses. But it’s easy to see when comparing Amazon EFS to OpenZFS and also EBS that they were not built to solve the same challenges. EFS wasn’t built to scale IOPs and throughput in the way that OpenZFS and EBS volumes do. These solutions are fundamentally different under the hood. Don’t get me wrong – if what one needs is high IOPs and high throughput and also full managed file storage, and if you do not get it – then you will have to design around it, often designing an architecture that ultimately, when one does attempt to move pieces of a workload closer to simplify will have to be re-architected in the future. The farther away you are in any part of an architecture, the more handoffs you have to do, the more cloning, and the weirder the networking the more expensive the solution.
Part 2 – Talk About the Past
In ’21 I was lucky to present on games industry migrations for Unity build farms with EC2 Mac at re:Invent alongside an amazingly talented team of Suvi Tanninen, Sergey Kurson, Eugene Krasikov, Trevor Roberts, and Unity itself. Together our group released multiple public architectures.
I believe and have since ’19 that the games industry, and even other industries using game engines, were moving to create end-to-end build pipelines that are secure, stepped, micro-flows and fast. The narrative I was so obsessed with tracking was developers desire to commit code to one version control, have your scans run (security, tests) on that exact code without cloning, pump out a build in the cloud (not local), parallelize that build and feed it as much CPU (GPU if needed – but engines didn’t take advantage of GPU as much as they could) and pay that down. Do this as much as humanly possible on machines you could afford, and have it take as short amount of time as possible, measure that time and keep hitting that metric end-to-end. Try to cut out unnecessary networking. Unnecessary cloning. The older your version of Unreal or Unity? The worse this dream was. The bigger your game? The harder it was. The more assets you shoved into Perforce? Hard. Geographically dispersed because of covid? Harder. Baking? Harder. Using some specialized render pipelines? Forget being in the cloud. Cross-platform? Hard. Console. Hard.
The bigger your objects…Weird hard.
Everyone had to care about storage at the same time.
I’d like to tell a story about a time I didn’t know who I was talking to – to explain why talking about what customers want, and getting closer to the problem is more effective than talking about the solution you think you are building.
The Elevator Pitch About Everyone Else
A generous portion of reInvent 2021 attendees were attending the re:Play rave. I’m a huge introvert, so 130 db hangers filled Zedd fans were only fun for me for about five minutes. The moments I enjoy the most are 1:1s. I escaped the “rave” and walked into a tent starving; it was good time to get food. There were only a handful of people sprinkled around the food tent. I grabbed some chicken….sat down in front of 1 person with no one really sitting anywhere near us and said “Hi. I’m Molly, I work for Amazon – who are you?” Wasn’t sure if he was a customer. It was kind of dark.
He simply introduced himself as Kevin. Said he “managed a bunch of people in S3.” In retrospect – I get why. If you’re reading, you can laugh.

I was REALLY EXCITED to talk about STORAGE. CLEARLY. “We started chatting about storing really big objects in S3.” We did – but mostly I decided I just wanted to tell him a ton of stories about what everyone was trying to build and how hard it was so somehow the S3 team could get it if I was lucky. I just hoped any of that excitement and energy would morph into good and I knew I didn’t have their perspective.
I remember him smiling. A lot. And listening. Alot. He clearly realized I had no idea who he was and took full advantage of the transparency.
Fast forward and this hits my LinkedIn in less than 24 hours and I realized that I had been talking to the VP of S3 while eating chicken wings surrounded by EDM music in light up heelies.
Get In The Hardest Place
I am supremely happy with my company (Take-Two / Zynga), my dream team (<3) , and the problems we solve. I wanted to share this story to show just how long it takes to solve really hard problems and that there is no loss (as long as you keep your NDAs) in saying – this is where I’ve been. This is what we saw. This is what I’ve lived. You may have to “move around” a problem you care about as you learn the different technologies people use to interact with that problem – you may start picking up Kubernetes because you know it’s a critical part of the workloads that you care about. Ultimately, you can fall in love with a problem, an industry, and not be able to give that up.
Keep solving the problems that make you excited enough to champion those you care about- it’s hard to get perspective. If you follow me because you are just now starting your career and someone asks you “If you had 5 minutes in an elevator with your CEO, what would you say” – know your problem as a champion of the customers it affects through the lens of opportunity as increased by paying down time.
Perhaps, if you keep trying to move closer and closer to the problem, move around the architecture and what people are actually doing in it, you can get close enough to believe our hardest problems are truly solvable.
I am excited about the Kubernetes CSI Driver for Amazon FSx for OpenZFS – cause I’ve not gotten to try it but mostly, I hope people continue to talk a ton about their problems in what is an extremely exciting industry to champion.
—
More On The Header Image From Wikipedia: “Integrated flux nebulas are a relatively recently identified astronomical phenomenon. In contrast to the typical and well known gaseous nebulas within the plane of the Milky Way galaxy, IFNs lie beyond the main body of the galaxy. The term was coined by Steve Mandel who defined them as ‘high galactic latitude nebulae that are illuminated not by a single star (as most nebula in the plane of the Galaxy are) but by the energy from the integrated flux of all the stars in the Milky Way. As a result, these nebulae are incredibly faint, taking hours of exposure to capture.‘”