I feel fortunate that a kind engineer told me yesterday “Thank you for your bluntness.” I owe her a World of Warcraft mythic. I appreciated that comment. Sometimes when I’m passionate about something, I just say it.
Let’s start with the bluntless – Companies still do not list Jr Engineering positions for Kubernetes. We would need a business desire…OR, ironically, maybe companies already have a path but haven’t lit it up. Or…companies are training our own people still. Or all of these things are true. Or they do list them but don’t say Kubernetes.
Patience is the calibration metric for which I evaluate if something will take 3 months, 6 months, 18 months, or never and quit your job. To solve this problem we need mild patience but also truly understand the problem we’re trying to solve. Throwing money at the “Hire interns for K8s” will only make it so much faster because we have to know a lot of information and that starts by sharing it. There are many links to training in this post based on my thankfulness for where we are today.
If you read this awesome Q4 ’22 Kubernetes Job Market report from Kube Careers, and one really should as it’s fantastic, readers will notice there is a slide for “How much work experience do companies seek for a Kubernetes role?” and see that almost 0 prefer individuals with 0-1 year experience while 75% of companies hire engineers or architects with 4-6 years of experience. Many roles do not list experience. It’s easy to shrug it off and say “Well it’s just too complicated!” That’s if one is not interested in the facets and that there’s probably opportunity there. In the spirit of “letting go things I don’t want to own” run with it if you want to. It’s probably an opportunity for providers, vendors, trainers, and companies alike.
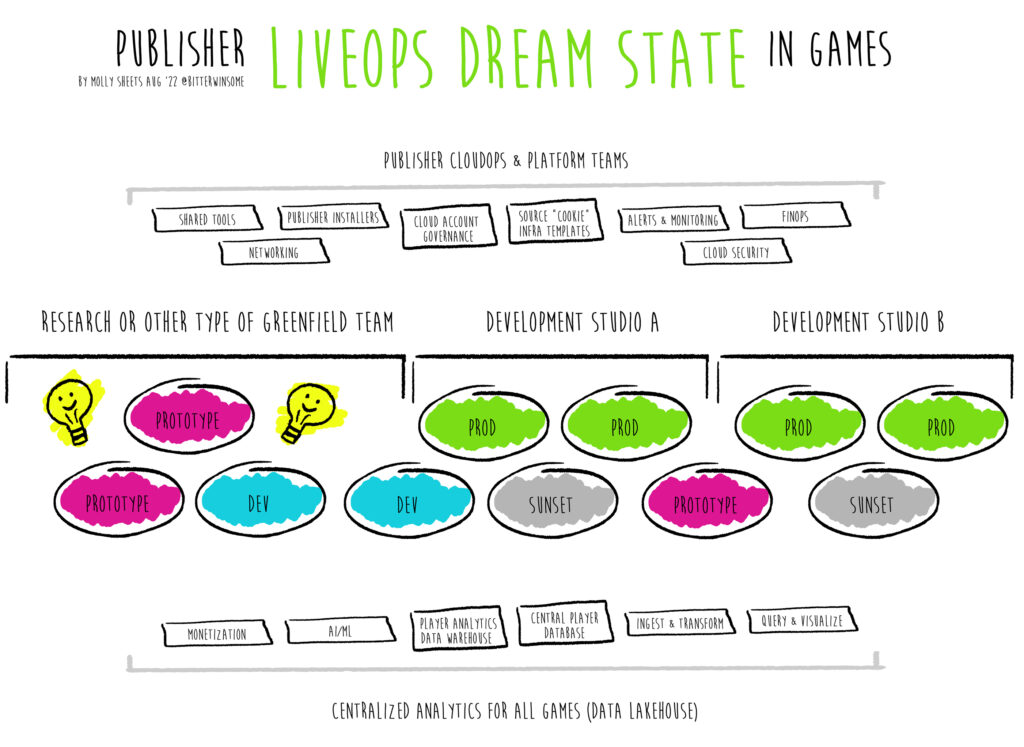
When I’m asked “Why do companies not list junior engineer positions or internships for Kubernetes teams!?” There is a fair and implied, “You should be doing something about this!” It’s an interesting perspective that implies… list the job under you because I know you and that’s where it should live. However I caution: There are many companies using Kubernetes but don’t necessarily call a team “the Kubernetes team” and many jobs listed that don’t have experience because they just don’t know and do not want to screw themselves out of the right applicant. Having a “Kubernetes team” is an implied centralized organizational construct. If a team calls itself the “Kubernetes team” they are centralizing thought leadership, looking around corners, and accountability for the “under the hood” components on that construct while simultaneously working to define what it isn’t responsible for to give others responsibility. When you begin to draw boundaries for what you manage and what you don’t as a team and a business around infrastructure you begin to have to define SLAs, SLOs, products, services, support for that business, or, group of businesses.
Ask anyone to define true uptime for Kubernetes who truly knows it and they will have a slight panic attack – because while you could have only SLOs for the applications or key endpoints, the reality is…
The theoretical maximum for distributed availability with dependencies in a cluster that has hundreds of them (apps, components, and hardware) is holy crap fun math that involves people!

You could just lie and say the cluster is always up even if you’re deleting nodes all the time and redeploying apps and occasionally the add-ons fall apart on themselves (having their own uptime), admit that you are only declaring uptime for 1 or 2 components, or just app SLOs, and you use that to determine business success. You may share something with customers around that while trying not to overwhelm them with truly how many dashboards you manage daily. You could do it based on incident length after you’ve declared one and severity. Or you could buy a service mapping SaaS product where they try to solve CAP theorem and political constructs for team topologies in the same tool. Those are the options.
Kubernetes teams don’t list Jr Engineers always because “Kubernetes Team” is an organizational construct we made up to divide lines around distributed availability in microservices in order to lower the blast radius of incidents and make deployments faster – but anyone who touches a Kubernetes cluster is a Kubernetes engineer. That’s where this blog begins cause that’s what fascinated me in March ’22.
Age of The Technologies Involved & Ease of Use
Let’s hope in 1.5 years the macro economic climate that is making it challenging to hire anyone is no longer a problem. That gives us a time window to solve the fundamental challenges that existed before the stock market fell apart. It’s a good window if we use it well and the right people tackle it; however, part of the problem is understanding many Kubernetes roles are there, but they aren’t necessarily under people like me! They are also still responsible for uptime!
What we have not solved: We have not clarified the path for hiring managers, universities, cloud providers with funny money, and students wanting to land in a role in 1.5-2 years in infrastructure. We have not said how we pay down the time from 0 to 6 years experience required to instead be 2 years experience. Because to get to 0-1 in a job post, we at least need to get to 2 years experience listed in job functions…But one mind blowing thing I realized last year is that Kubernetes Roles with 2 years experience do exist….they just aren’t listed as Kubernetes roles and thus don’t get picked up in reports. I’m going to Quentin Tarantino this and then if you graduate in 2 years you are going to apply to be a Site Reliability Engineer or a Backend Server Developer or eventually join a Developer Experience or Kubernetes Team if, and that’s only if, you want to manage maintenance and quality of “under the hood” aspects. If that’s not interesting after evaluation, engineers then go live in an app or game team with server-side deployments.
Kubernetes, an open-source ecosystem for automating deployment, horizontally scaling across hardware, and management of containers, is not the only technology involved in Kubernetes. I would say “sadly” but this complexity currently keeps many employed. Simplifying complexity is a great way to keep a job. Kubernetes was introduced in 2014 right after the dying of Flash took out half the games industry in layoffs. Very few people were able to manage both adoption of microservices and also that client-side chaos. The ones that excelled adopted both Unity, to build client-side binaries for games, and microservices in the backend. In infrastructure it can take 5 years to see adoption at scale. I feel so lucky to be surrounded by teams of avengers who care about “Kubernetes” but many do not know what they (have to) care about because the technology is still new in the evolutionary timescale of infrastructure. Kubernetes architects, can be split into – Security, Infrastructure, and App maintainer and all of these roles have different aspects they have to manage with sub-roles. I spend a lot of days laughing while crying with these wonderful people which is why I love my job and not all of them are on my team.
I didn’t start with Kubernetes and neither did anyone I know.
Learning Kubernetes Requires One to Learn Infrastructure
To learn Kubernetes, we first have to learn Cloud 101. This includes, but is not limited to, how to create accounts in specific providers, how to secure them, basic networking, compute, and storage. This also includes learning fundamental security principles such as identity and access management roles and policies and honing in on a provider. It took me about 2 years to pick this up somewhat deeply and that’s only because now I know how much more complicated it can get (also that link is a 200 level talk and reInvent talks go up to 400). Cloud has accelerated individuals to pick up infrastructure generally – it’s much easier to learn backend when one can spin it up in 5 minutes in a sandbox verse having to buy it from a data center down the street.
A lot of the hard training work has been done by cloud providers. In 2018-2019 at AWS there was little games focused infrastructure material. So when I say “we are getting there,” I truly mean it. There were so many bricks that had to be laid before we got here in games. The more training put out there, the more free and accessible, the faster it continues to become to learn. I’ll share AWS Certification portal which has a bunch of free material – Click here for free stuff where I promise I did not link to a thinly veined phishing attempt or Rick Astley. If you are an engineer in college and have an open summer, don’t burn it – get certified or go through the basic AWS fundamentals (or preferred cloud provider for the company you want to work for) on A Cloud Guru. If you can stick even a single AWS certification (Solutions Architect Associate or Developer) on your resume as a recent grad you already will stand out.
Ironically, even though Kubernetes came out of Google and is OpenSource, in Kube Careers ’22 dataset of 373 jobs, 300 (80%) mention AWS as the preferred infra location – 40% of tags mentioned AWS where as GCP and Azure were 22% and 21%. People think that I picked AWS because I worked at AWS. I picked AWS before I worked at AWS and invested in my career in it. 2 years into my business we swapped from Azure to AWS due to ease of use (I know, I realize AWS is complex and now Azure and GCP is more simple. I still believe AWS’s too many services and lack of consolidation / defiance of deprecating and merging as a by product of systemic design… goes against Invent and Simplify. It’s mostly just reinvent. We’ll see what happens…).
For the LinkedIn people of the world – one person I admire who makes this all approachable and consumable is Viktoria Semaan – Follow her and “non-doom” scroll a few times a week and you will rapidly pick up random cloud knowledge that may save you pain in the future. She’s an expert at simplifying and cares about the pain points in a functional way. Take any Social Media time you spend resisting the urge to yell at people and instead, watch her short videos, and you will become smarter.
Then Learn Infrastructure as Code
I remember I spent several weeks last year going back and forth with a great individual at AWS, Larry Scott, about our industry needs for Infrastructure as Code to be taught at the university level. I say this because engineers in enterprise should not touch infrastructure directly in the accounts, but that’s where many start. In fact, that’s where the industry itself started. If one picks up infrastructure as code today in university and does not wait, they will be ahead. There are still individuals who have high paying senior engineering and architecture positions who are now learning Terraform and that’s okay.
Then Learn the Kubernetes Control Plane & Worker Nodes and all of the Changes that come with It
Okay, now that we know cloud and infrastructure as code, we can learn Kubernetes. If you want to cry with appreciation at how so much is handled for you by cloud providers, you can Learn Kubernetes the Hard Way which will teach an engineer to appreciate the amazing Kelsey Hightower as a person. However, we’re trying to get peers jobs, so for “speed” I recommend taking the Certified Kubernetes Administrator (CKA) course instead. This may actually land a person quickly into a Site Reliability Engineering role.
Looking at the Cloud Native Computing Foundation’s Annual Survey from ’22, over 50% of survey respondents manage more than 10 clusters and 19% manage 6-10 clusters. 64% of CNCF end users (members that use cloud but do not sell cloud native services and aren’t vendors) use Kubernetes in production. Companies in that state need people to watch those clusters. A well organized team understands the shared responsibility between SRE and the infrastructure management teams – infrastructure’s job is to make sure SRE doesn’t get a ton of alerts all the time and SRE’s job is to be the first line of defense because nothing is perfect. If things were perfect we wouldn’t have incidents and a fully-blown industry cultural movement that’s survived for years called #hugops created for empathy when no one else cared because we still beat people up for outages even in micro-contexts and are learning, wait, they aren’t that bad most of the time anymore because we’ve designed isolated constraints.
If an engineer can prove they can manage commands in a cluster, people will trust that person to run commands in playbooks. That’s a totally reasonable place to start and a well paying job that many stay in because SRE people are funny, smart, and kind. So while there may not be a ton of junior “Kubernetes” roles there are; however, many SRE roles in every industry that uses K8s. SREs are everyday fire fighters and we should send them lots of gif(ts). Sometimes they live in the same org and sometimes they don’t.
Then… Kubernetes Needs a bunch of Add-Ons…Hyper Tooling for App Deployments…Or maybe Auxiliary Workloads?
I wish the control plane and worker nodes and just managing upgrades of those things while trying to keep applications always on with no downtime was where the jobs stop but it doesn’t. Or maybe I don’t know. I don’t know. Once you know basic Kubernetes you realize “uptime” is actually both the applications on the cluster, the cluster itself, and all the components you’ve installed on it – agents, add-ons, networking configurations…on top of any surrounded or co-related infrastructure that connects to it (and all the questions that come with those things).
My favorite graph from the CNCF Foundation’s ’22 report (which, please, check out the whole report) is actually this one:

Auxiliary workloads are workloads running on a cluster that aren’t actually the applications. Sounds weird right? It’s not – people throw all kinds of things on clusters and around Kubernetes clusters. Build pipelines. Logging. Monitoring. Connect them to databases to manage Terraform state. This can evolve into entire teams managing just a piece of the workload while another still manages the rest – which is why you could go learn ArgoCD, Flux, Docker, Grafana, GitHub Actions, Jenkins, Kyverno, DataDog, Honeycomb, Open Telemetry, AWS Secrets Manager, Splunk and still land at “a Kubernetes Job.” Hell if you just learn Go extremely deeply you’ll probably get a job. “My whole team wants to learn Go” is a real quote I’ve heard 3 times. It’s now the 2nd most popular language behind Python. Or if you’re me, you’re reading about solutions like Rootly.com and Jeli.io cause they seem helpful but low key are following those spaces with a ton of patience. The CNCF landscape is huge and if you build in it or adopt parts of it incorrectly you’ve signed yourself up for business pain.
Customers Will Always Want An Infrastructure Team to Manage Kubernetes…even in a Self Service World and You need a Community – That Community is all the People who have Jobs Around It
Companies want Kubernetes teams to manage upgrades for all of those above things, all components, and then have jobs focus on the usability, vendor management, and performance of all of those components. Maintenance and quality around upgrades is something so involved that AWS has focused deeply on it. If you don’t want those things you try to build on Fargate and Lambda or GKE because “it’s simple” just to realize it’s not simple and still requires thought leadership and guardrails of their own kind.
However if you’ve read this far and thought, “I just want to build around people like you and I did the Cloud stuff, and the CKAD stuff,” and start to realize, which this is not a lot of people okay, I’ve rarely convinced truly, that safe maintenance and working towards testing in production through isolated constructs, canary deployments, and more and this is what you care about…This is what to learn deeply:
- How do I plan an Upgrade Strategy for Amazon EKS?
- Updating an Amazon EKS Cluster Kubernetes Version
- Planning Kubernetes Upgrades with Amazon EKS
- Amazon EKS Improves Control Plane Scaling & Update Speed by Up to 4x
- Eksworkshop.com
- Making sure apps don’t have downtime specifically in games contexts that are not just game servers…but all the games use cases…
People who learn the above will excel in enterprise business, AA, AAA games. The biggest take away from this post is as an applicant – learn anything in this ecosystem in the next 2 years. Look up any nebulous terms I’ve mentioned, explore them. Take the A Cloud Guru CKA and CKAD courses (you don’t need to do the official exam). Take Derek Morgan‘s training material on More Than Certified and follow him for the devops memes. The material is there today and it wasn’t 5 years ago.
Dive in and use the “keywords” to find your dream job. You don’t have to search “Kubernetes” – you can search literally any thing – Jenkins, Splunk, Observability, App Deployments, and it will probably still land you at…Kubernetes. But if you want to actually “Do Kubernetes” (and not the apps, or security, or anything else on top of it) then that’s maintaining it. Get really good at that – start with the add-ons, then the control plane, understand how they work, what they do, and what we screw up when it goes wrong and that it’s okay.
In Conclusion
This was the most rambly post I’ve written because I can’t output what is in my brain around this fast enough. If I had more time I would have organized it. I have not solved this problem, but many, many people are trying. What I can tell you is that “Kubernetes Team” at almost every company, not just games, is an organizational construct with a focus in the same way “Chief Metaverse Officer” is not an organizational construct because it has no focus. Kubernetes focus can be divided into a few key parts, mainly based on tooling and roles/responsibility. Depending on what you like to do in that ecosystem you may live in another castle. What any team does is going to be based on their mission and who they report to when in complexity.
As long as you are learning some of the tooling or software or links in this post, you will get an engineering role by the time we have finally figured out how we need to properly list the organizational constructs ourselves as the games industry. In general, any industry using Kubernetes with the right experience level that will meet individuals where they are in that journey. A mentor shared me a post that a blog is a query to find your people – so if you can’t find the job….write about what you are building towards your future on social media until they start showing up in your cookies. Do that and you’ll never not find your people.
PS. I didn’t link to Rick Astley earlier because I didn’t want to Rick Roll in this post, but if I was going to do it with class…I wouldn’t link to the original video. I would link to one that would spawn a discussion about how you shouldn’t care what people think about your career and do whatever makes you happy and find those people who are happy around you…and Dave Grohled you through Rick Astley instead.
PPS. Kube Careers is really fantastic https://kube.careers/ idea, and I’m pretty excited generally about what LearnK8s is doing. They are also a great small team to follow on LinkedIn and frequently share repositories.